Request和Response对象
Request对象:
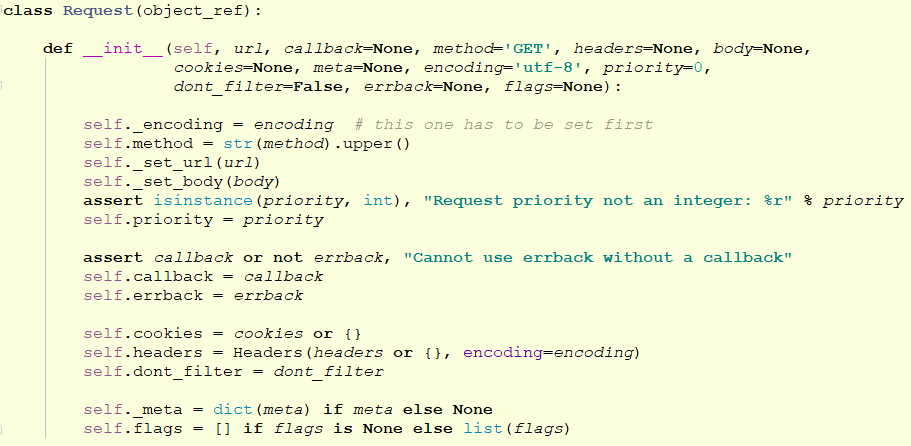
Request对象在我们写爬虫,爬取一页的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有:
url:这个request对象发送请求的url。callback:在下载器下载完相应的数据后执行的回调函数。method:请求的方法。默认为GET方法,可以设置为其他方法。headers:请求头,对于一些固定的设置,放在settings.py中指定就可以了。对于那些非固定的,可以在发送请求的时候指定。meta:比较常用。用于在不同的请求之间传递数据用的。encoding:编码。默认的为utf-8,使用默认的就可以了。dont_filter:表示不由调度器过滤。在执行多次重复的请求的时候用得比较多。errback:在发生错误的时候执行的函数。
Response对象:
Response对象一般是由Scrapy给你自动构建的。因此开发者不需要关心如何创建Response对象,而是如何使用他。Response对象有很多属性,可以用来提取数据的。主要有以下属性:
- meta:从其他请求传过来的
meta属性,可以用来保持多个请求之间的数据连接。 - encoding:返回当前字符串编码和解码的格式。
- text:将返回来的数据作为
unicode字符串返回。 - body:将返回来的数据作为
bytes字符串返回。 - xpath:xapth选择器。
- css:css选择器。
发送POST请求:
有时候我们想要在请求数据的时候发送post请求,那么这时候需要使用Request的子类FormRequest来实现。如果想要在爬虫一开始的时候就发送POST请求,那么需要在爬虫类中重写start_requests(self)方法,并且不再调用start_urls里的url。
模拟登录
案例一:模拟登录人人网
案例二:模拟登录豆瓣网(识别验证码)
图形验证码识别平台:https://market.aliyun.com/products/57126001/cmapi014396.html#sku=yuncode839600006